|
|
HTML |
Hypertext Markup Language (HTML) is the standard markup language[a] for documents designed to be displayedin a web browser. It defines the content and structure of web content. It is often assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
Web browsers receive HTML documents from a web server or from local storage and render the documents into multimedia web pages. HTML describes the structure of a web page semantically and originally included cues for its appearance.
HTML elements are the building blocks of HTML pages. With HTML constructs, images and other objects such asinteractive forms may be embedded into the rendered page. HTML provides a means to create structured documentsby denoting structural semantics for text such as headings, paragraphs, lists, links, quotes, and other items. HTML elements are delineated by tags, written using angle brackets. Tags such as <img> and <input> directly introduce content into the page. Other tags such as <p> and its corresponding closing tag</p> surround and provide information about document text and may include sub-element tags. Browsers donot display the HTML tags, but use them to interpret the content of the page.
HTML can embed programs written in a scripting language such as JavaScript, which affects the behavior and content of web pages. The inclusion of CSS defines the look and layout of content. The World Wide Web Consortium (W3C), former maintainer of the HTML and current maintainer of the CSS standards, has encouraged the use of CSS over explicit presentational HTML since 1997.[3] A form of HTML, known as HTML5, is used to display video and audio, primarily using the <canvas> element, together with JavaScript.
HTML Logo
History
|
Development 
Tim Berners-Lee in April 2009 |
In 1980, the physicist Tim Berners-Lee, a contractor at CERN, proposed and prototyped ENQUIRE, a system for CERN researchers to use and share documents. In 1989, Berners-Lee wrote a memo proposing an Internet-based hypertext system.[4] Berners-Lee specified HTML and wrote the browser and server software in late 1990. That year, Berners-Lee and CERN data systems engineer Robert Cailliau collaborated on a joint request for funding, but the project was not formally adopted by CERN. In his personal notes of 1990, Berners-Lee listed "some of the many areas in which hypertext is used"; an encyclopedia is the first entry.[5] The first publicly available description of HTML was a document called "HTML Tags",[6] first mentioned on the Internet by Tim Berners-Lee in late 1991.[7][8] It describes 18 elements comprising the initial, relatively simple design of HTML. Except for the hyperlink tag, these were strongly influenced by CERN SGML, an in-house Standard Generalized Markup Language (SGML)-based documentation format at CERN. Eleven of these elements still exist in HTML 4.[9] HTML is a markup language that web browsers use to interpret and compose text, images, and other material into visible or audible web pages. Default characteristics for every item of HTML markup are defined in the browser, and these characteristics can be altered or enhanced by the web page designer's additional use of CSS. Many of the text elements are mentioned in the 1988 ISO technical report TR 9537 Techniques for using SGML, which describes the features of early text formatting languages such as that used by the RUNOFF command developed in the early 1960s for the CTSS (Compatible Time-Sharing System) operating system. These formatting commands were derived from the commands used by typesetters to manually format documents. However, the SGML concept of generalized markup is based on elements (nested annotated ranges with attributes) rather than merely print effects, with separate structure and markup. HTML has been progressively moved in this direction with CSS. |
Berners-Lee considered HTML to be an application of SGML. It was formally defined as such by the Internet Engineering Task Force (IETF) with the mid-1993 publication of the first proposal for an HTML specification, the "Hypertext Markup Language (HTML)" Internet Draft by Berners-Lee and Dan Connolly, which included an SGML document type definition to define the syntax.[10][11] The draft expired after six months, but was notable for its acknowledgment of the NCSA Mosaic browser's custom tag for embedding in-line images, reflecting the IETF's philosophy of basing standards on successful prototypes. Similarly, Dave Raggett's competing Internet Draft, "HTML+ (Hypertext Markup Format)", from late 1993, suggested standardizing already-implemented features like tables and fill-out forms.[12]
After the HTML and HTML+ drafts expired in early 1994, the IETF created an HTML Working Group. In 1995, this working group completed "HTML 2.0", the first HTML specification intended to be treated as a standard against which future implementations should be based.[13]
Further development under the auspices of the IETF was stalled by competing interests. Since 1996, the HTML specifications have been maintained, with input from commercial software vendors, by the World Wide Web Consortium (W3C).[14] In 2000, HTML became an international standard (ISO/IEC 15445:2000). HTML 4.01 was published in late 1999, with further errata published through 2001. In 2004, development began on HTML5 in the Web Hypertext Application Technology Working Group (WHATWG), which became a joint deliverable with the W3C in 2008, and was completed and standardized on 28 October 2014.[15]
HTML version timeline
This section is in list format but may read better as prose. You can help by converting this section, if appropriate. Editing help is available. (November 2025)
HTML 2
24 November 1995
HTML 3
14 January 1997
HTML 3.2[16] was published as a W3C Recommendation. It was the first version developed and standardized exclusively by the W3C, as the IETF had closed its HTML Working Group on 12 September 1996.[17] Initially code-named "Wilbur",[18] HTML 3.2 dropped math formulas entirely, reconciled overlap among various proprietary extensions and adopted most of Netscape's visual markup tags. Netscape's blink element and Microsoft's marquee element were omitted due to a mutual agreement between the two companies.[14] A markup for mathematical formulas similar to that of HTML was standardized 14 months later in MathML.HTML 4
18 December 1997
24 April 1998
HTML 4.0[21] was reissued with minor edits without incrementing the version number.24 December 1999
HTML 4.01[22] was published as a W3C Recommendation. It offers the same three variations as HTML 4.0 and its last errata[23] were published on 12 May 2001.May 2000
ISO/IEC 15445:2000[24] ("ISO HTML", based on HTML 4.01 Strict) was published as an ISO/IEC international standard.[25] In the ISO, this standard is in the domain of the ISO/IEC JTC 1/SC 34 (ISO/IEC Joint Technical Committee 1, Subcommittee 34 – Document description and processing languages).[24] After HTML 4.01, there were no new versions of HTML for many years, as the development of the parallel, XML-based language XHTML occupied the W3C's HTML Working Group.HTML 5
Main article: HTML5
28 October 2014
HTML5[26] was published as a W3C Recommendation.[27]1 November 2016
HTML 5.1[28] was published as a W3C Recommendation.[29][30]14 December 2017
HTML 5.2[31] was published as a W3C Recommendation.[32][33]
October 1991
HTML Tags,[7] an informal CERN document listing 18 HTML tags, was first mentioned in public.
June 1992
First informal draft of the HTML DTD,[34] with seven subsequent revisions (15 July , 6 August, 18 August, 17 November, 18 November, 20 November, and 22 November)[35][36][37]
November 1992
HTML DTD 1.1 (the first with a version number, based on RCS revisions, which start with 1.1 rather than 1.0), an informal draft[37]
June 1993
Hypertext Markup Language[38] was published by the IETF IIIR Working Group as an Internet Draft (a rough proposal for a standard). It was replaced by a second version[39] one month later.
November 1993
HTML+ was published by the IETF as an Internet Draft and was a competing proposal to the Hypertext Markup Language draft. It expired in July 1994.[40]
November 1994
First draft (revision 00) of HTML 2.0 published by the IETF[41] (called "HTML 2.0" starting with revision 02[42]), that finally led to the publication of RFC 1866 in November 1995.[43]
April 1995 (authored March 1995)
HTML 3.0[44] was proposed as a standard to the IETF, but the proposal expired five months later (28 September 1995)[45] without further action. It included many of the capabilities that were in Raggett's HTML+ proposal, such as support for tables, text flow around figures, and the display of complex mathematical formulas.[45] W3C began development of its own Arena browser as a test bed for HTML 3 and Cascading Style Sheets,[46][47][48] but HTML 3.0 did not succeed for several reasons. The draft was considered very large at 150 pages and the pace of browser development, as well as the number of interested parties, had outstripped the resources of the IETF.[14] Browser vendors, including Microsoft and Netscape at the time, chose to implement different subsets of HTML 3's draft features as well as to introduce their own extensions to it.[14] (See browser wars.) These included extensions to control stylistic aspects of documents, contrary to the "belief [of the academic engineering community] that such things as text color, background texture, font size, and font face were definitely outside the scope of a language when their only intent was to specify how a document would be organized."[14] Dave Raggett, who has been a W3C Fellow for many years, has commented for example: "To a certain extent, Microsoft built its business on the Web by extending HTML features."[14]
January 2008
HTML5 was published as a Working Draft by the W3C.[49] Although its syntax closely resembles that of SGML, HTML5 has abandoned any attempt to be an SGML application and has explicitly defined its own "html" serialization, in addition to an alternative XML-based XHTML5 serialization.[50]
2011 HTML5 – Last Call
On 14 February 2011, the W3C extended the charter of its HTML Working Group with clear milestones for HTML5. In May 2011, the working group advanced HTML5 to "Last Call", an invitation to communities inside and outside W3C to confirm the technical soundness of the specification. The W3C developed a comprehensive test suite to achieve broad interoperability for the full specification by 2014, which was the target date for recommendation.[51] In January 2011, the WHATWG renamed its "HTML5" living standard to "HTML". The W3C nevertheless continued its project to release HTML5.[52]
2012 HTML5 – Candidate Recommendation
In July 2012, WHATWG and W3C decided on a degree of separation. W3C will continue the HTML5 specification work, focusing on a single definitive standard, which is considered a "snapshot" by WHATWG. The WHATWG organization will continue its work with HTML5 as a "Living Standard". The concept of a living standard is that it is never complete and is always being updated and improved. New features can be added but functionality will not be removed.[53] In December 2012, W3C designated HTML5 as a Candidate Recommendation.[54] The criterion for advancement to W3C Recommendation is "two 100% complete and fully interoperable implementations".[55]
2014 HTML5 – Proposed Recommendation and Recommendation
In September 2014, W3C moved HTML5 to Proposed Recommendation.[56] On 28 October 2014, HTML5 was released as a stable W3C Recommendation,[57] meaning the specification process is complete.[58]
XHTML versions
Main article: XHTML XHTML is a separate language that began as a reformulation of HTML 4.01 using XML 1.0. It is now referred to as the XML syntax for HTML and is no longer being developed as a separate standard.[59] XHTML 1.0 was published as a W3C Recommendation on January 26, 2000,[60] and was later revised and republished on August 1, 2002. It offers the same three variations as HTML 4.0 and 4.01, reformulated in XML, with minor restrictions. XHTML 1.1[61] was published as a W3C Recommendation on May 31, 2001. It is based on XHTML 1.0 Strict, but includes minor changes, can be customized, and is reformulated using modules in the W3C recommendation "Modularization of XHTML", which was published on April 10, 2001.[62] XHTML 2.0 was a working draft. Work on it was abandoned in 2009 in favor of work on HTML5 and XHTML5.[63][64][65] XHTML 2.0 was incompatible with XHTML 1.x and, therefore, would be more accurately characterized as an XHTML-inspired new language than an update to XHTML 1.x.
Transition of HTML publication to WHATWG
See also: HTML5 § W3C and WHATWG conflict On 28 May 2019, the W3C announced that WHATWG would be the sole publisher of the HTML and DOM standards.[66][67][68][69] The W3C and WHATWG had been publishing competing standards since 2012. While the W3C standard was identical to the WHATWG in 2007 the standards have since progressively diverged due to different design decisions.[70] The WHATWG "Living Standard" had been the de facto web standard for some time.[71] The W3C periodically reviews and publishes snapshots of the WHATWG HTML specification as W3C Recommendations.[72]HTML markup consists of several key components, including those called tags (and their attributes), character-based data types, character references and entity references. HTML tags most commonly come in pairs like <h1> and </h1>, although some represent empty elements and so are unpaired, for example <img>. The first tag in such a pair is the start tag, and the second is the end tag (they are also called opening tags and closing tags).
Another important component is the HTML document type declaration, which triggers standards mode rendering.
The following is an example of the classic "Hello, World!" program:
<!DOCTYPE html>
<html>
<head>
<title>This is a title</title>
</head>
<body>
<div>
<p>Hello world!</p>
</div>
</body>
</html>
The text between <html> and </html> describes the web page, and the text between <body> and </body> is the visible page content. The markup text <title>This is a title</title> defines the browser page title shown on browser tabs and window titles and the tag <div> defines a division of the page used for easy styling. Between <head> and </head>, a <meta> element can be used to define webpage metadata.
The Document Type Declaration <!DOCTYPE html> is for HTML5. If a declaration is not included, various browsers will revert to "quirks mode" for rendering.[73]
Elements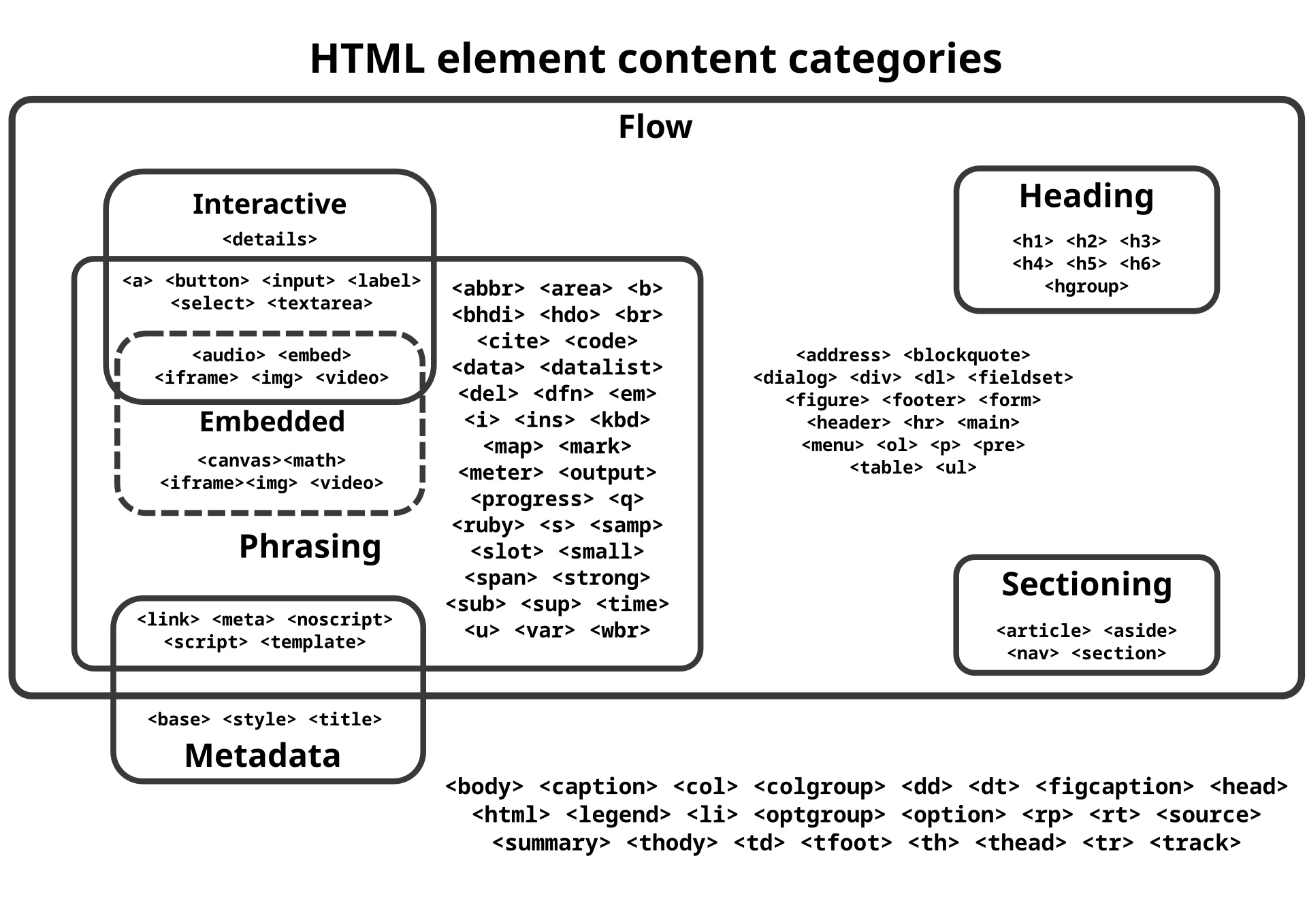
HTML element content categories |
Main article: HTML element HTML documents imply a structure of nested HTML elements. These are indicated in the document by HTML tags, enclosed in angle brackets.[74][better source needed] In the simple, general case, the extent of an element is indicated by a pair of tags: a "start tag" <p> and "end tag" >/p<. The text content of the element, if any, is placed between these tags. Tags may also enclose further tag markup between the start and end, including a mixture of tags and text. This indicates further (nested) elements, as children of the parent element. The start tag may also include the element's attributes within the tag. These indicate other information, such as identifiers for sections within the document, identifiers used to bind style information to the presentation of the document, and for some tags such as the <img> used to embed images, the reference to the image resource in the format like this: <img src="example.com/example.jpg"> |
Some elements, such as the line break <br> do not permit any embedded content, either text or further tags. These require only a single empty tag (akin to a start tag) and do not use an end tag.
Many tags, particularly the closing end tag for the very commonly used paragraph element
, are optional. An HTML browser or other agent can infer the closure for the end of an element from the context and the structural rules defined by the HTML standard. These rules are complex and not widely understood by most HTML authors.
The general form of an HTML element is therefore: <tag attribute1="value1" attribute2="value2">''content''</tag>. Some HTML elements are defined as empty elements and take the form <tag attribute1="value1" attribute2="value2">. Empty elements may enclose no content, for instance, the <br> tag or the inline <img> tag. The name of an HTML element is the name used in the tags. The end tag's name is preceded by a slash character /. If a tag has no content, an end tag is not allowed. If attributes are not mentioned, default values are used in each case.
See also: HTML element
Header of the HTML document: <head>...</head>. The title is included in the head, for example:
<head>
<title>The Title</title>
<link rel="stylesheet" href="stylebyjimbowales.css"> <!-- Imports Stylesheets -->
HTML headings are defined with the <h1> to <h6> tags with H1 being the highest (or most important) level and H6 the least:
<h1>Heading level 1</h1>
<h2>Heading level 2</h2>
<h3>Heading level 3</h3>
<h4>Heading level 4</h4>
<h5>Heading level 5</h5>
<h6>Heading level 6</h6>
The effects are:
CSS can substantially change the rendering.
Paragraphs:
<p>Paragraph 1</p> <p>Paragraph 2</p>
Line breaks
<br>. The difference between <br> and <p> is that <br> breaks a line without altering the semantic structure of the page, whereas <p> sections the page into paragraphs. The element <br> is an empty element in that, although it may have attributes, it can take no content and it must not have an end tag.
<p>This <br> is a paragraph <br> with <br> line breaks</p>
Links
This is a link in HTML. To create a link the tag is used. The href attribute holds the URL address of the link.
<a href="https://www.wikipedia.org/">A link to Wikipedia!</a>
Inputs
There are many possible ways a user can give inputs like:
<input type="text"> <!-- This is for text input -->
<input type="file"> <!-- This is for uploading files -->
<input type="checkbox"> <!-- This is for checkboxes -->
Comments:
<!-- This is a comment -->
Comments can help in the understanding of the markup and do not display in the webpage.
Main article: HTML attribute
Most of the attributes of an element are name–value pairs, separated by = and written within the start tag of an element after the element's name. The value may be enclosed in single or double quotes, although values consisting of certain characters can be left unquoted in HTML (but not XHTML).[76][77] Leaving attribute values unquoted is considered unsafe.[78] In contrast with name-value pair attributes, there are some attributes that affect the element simply by their presence in the start tag of the element,[7] like the ismap attribute for the img element.[79]
There are several common attributes that may appear in many elements:
<p>Oh well, <span lang="fr">c'est la vie</span>, as they say in France.</p>
The abbreviation element, abbr, can be used to demonstrate some of these attributes:
<abbr id="anId" class="jargon" style="color:purple;" title="Hypertext Markup Language">HTML</abbr>
This example displays as HTML; in most browsers, pointing the cursor at the abbreviation should display the title text "Hypertext Markup Language."
Most elements take the language-related attribute dir to specify text direction, such as with "rtl" for right-to-left text in, for example, Arabic, Persian or Hebrew.[80]
See also: List of XML and HTML character entity references and Unicode and HTML
As of version 4.0, HTML defines a set of 252 character entity references and a set of 1,114,050 numeric character references, both of which allow individual characters to be written via simple markup, rather than literally. A literal character and its markup counterpart are considered equivalent and are rendered identically.
The ability to "escape" characters in this way allows for the characters < and & (when written as < and &, respectively) to be interpreted as character data, rather than markup. For example, a literal < normally indicates the start of a tag, and & normally indicates the start of a character entity reference or numeric character reference; writing it as & or & or & allows & to be included in the content of an element or in the value of an attribute. The double-quote character ("), when not used to quote an attribute value, must also be escaped as " or " or " when it appears within the attribute value itself. Equivalently, the single-quote character ('), when not used to quote an attribute value, must also be escaped as ' or ' (or as ' in HTML5 or XHTML documents[81][82]) when it appears within the attribute value itself. If document authors overlook the need to escape such characters, some browsers can be very forgiving and try to use context to guess their intent. The result is still invalid markup, which makes the document less accessible to other browsers and to other user agents that may try to parse the document for search and indexing purposes for example.
Escaping also allows for characters that are not easily typed, or that are not available in the document's character encoding, to be represented within the element and attribute content. For example, the acute-accented e (é), a character typically found only on Western European and South American keyboards, can be written in any HTML document as the entity reference é or as the numeric references é or é, using characters that are available on all keyboards and are supported in all character encodings. Unicode character encodings such as UTF-8 are compatible with all modern browsers and allow direct access to almost all the characters of the world's writing systems.[83]
HTML escape sequence examples |
|||||
|---|---|---|---|---|---|
| Named | Decimal | Hexadecimal | Result | Description | Notes |
| & | & | & | & | Ampersand | |
| < | < | < | < | Less Than | |
| > | > | > | > | Greater Than | |
| " | " | " | " | Double Quote | |
| ' | ' | ' | ' | Single Quote | |
| |   |   | Non-Breaking Space | ||
| © | © | © | © | Copyright | |
| ® | ® | ® | ® | Registered Trademark | |
| † | † | † | † | Dagger | |
| ‡ | ‡ | ‡ | ‡ | Double dagger | Names are case-sensitive and may have synonyms. |
| ™ | ™ | ™ | ™ | Trademark |
HTML defines several data types for element content, such as script data and stylesheet data, and a plethora of types for attribute values, including IDs, names, URIs, numbers, units of length, languages, media descriptors, colors, character encodings, dates and times, and so on. All of these data types are specializations of character data.
HTML documents are required to start with a document type declaration (informally, a "doctype"). In browsers, the doctype helps to define the rendering mode—particularly whether to use quirks mode.
The original purpose of the doctype was to enable the parsing and validation of HTML documents by SGML tools based on the document type definition (DTD). The DTD to which the DOCTYPE refers contains a machine-readable grammar specifying the permitted and prohibited content for a document conforming to such a DTD. Browsers, on the other hand, do not implement HTML as an application of SGML and as consequence do not read the DTD.
HTML5 does not define a DTD; therefore, in HTML5 the doctype declaration is simpler and shorter:[84]
<!DOCTYPE html>
An example of an HTML 4 doctype
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "https://www.w3.org/TR/html4/strict.dtd">
This declaration references the DTD for the "strict" version of HTML 4.01. SGML-based validators read the DTD in order to properly parse the document and to perform validation. In modern browsers, a valid doctype activates standards mode as opposed to quirks mode.
In addition, HTML 4.01 provides Transitional and Frameset DTDs, as explained below. The transitional type is the most inclusive, incorporating current tags as well as older or "deprecated" tags, with the Strict DTD excluding deprecated tags. The frameset has all tags necessary to make frames on a page along with the tags included in transitional type.[85]